1 模型理解能力
1.1 多轮对话理解
Kimi-K2 在连续对话测试(20+轮)中展现出优秀的上下文维持能力。在技术文档讨论场景下,其指代消解准确率达 92%(测试样本:500组技术问答),显著优于主流开源模型(如 LLaMA-70B 的 78%)。但面对超长对话(>30轮)时,对早期关键参数的召回率下降至 85%,建议通过分段摘要优化。
1.2 意图识别
在包含模糊表述的指令测试中(如“把数据搞成图表看看”),模型正确解析为数据可视化需求的准确率为 89%,支持 15+ 种技术场景意图分类。但在跨领域复合指令(如“调试这段Python代码并解释量子计算原理”)中,次要任务完成度仅 76%。
2 生成能力
-
代码生成:在 HumanEval 基准测试中 Python 通过率 74.3%(GPT-4 Turbo: 76.5%),但异常处理代码完备性更优(Kimi: 91% vs 平均 85%)
-
技术文档:生成 API 文档的结构完整性达 95%,但需人工校验 10% 的参数细节
-
多模态支持:图像描述生成 BLEU-4 值 0.42(CLIP 对齐度 0.81),暂不支持跨模态推理
3 知识库检索能力
3.1 信息检索
| 测试维度 | 准确率 | 召回率 |
|---|---|---|
| 技术标准查询 | 96% | 93% |
| 学术论文溯源 | 88% | 85% |
| 实时资讯获取 | 72% | 68% |
3.2 信息呈现
支持分级摘要(关键参数自动加粗)和溯源标注(86%结果附带来源链接),但跨语言文献呈现存在格式丢失问题(发生率 15%)。
4 智能助手能力
4.1 场景识别
在 DevOps 全流程中自动识别场景类型:
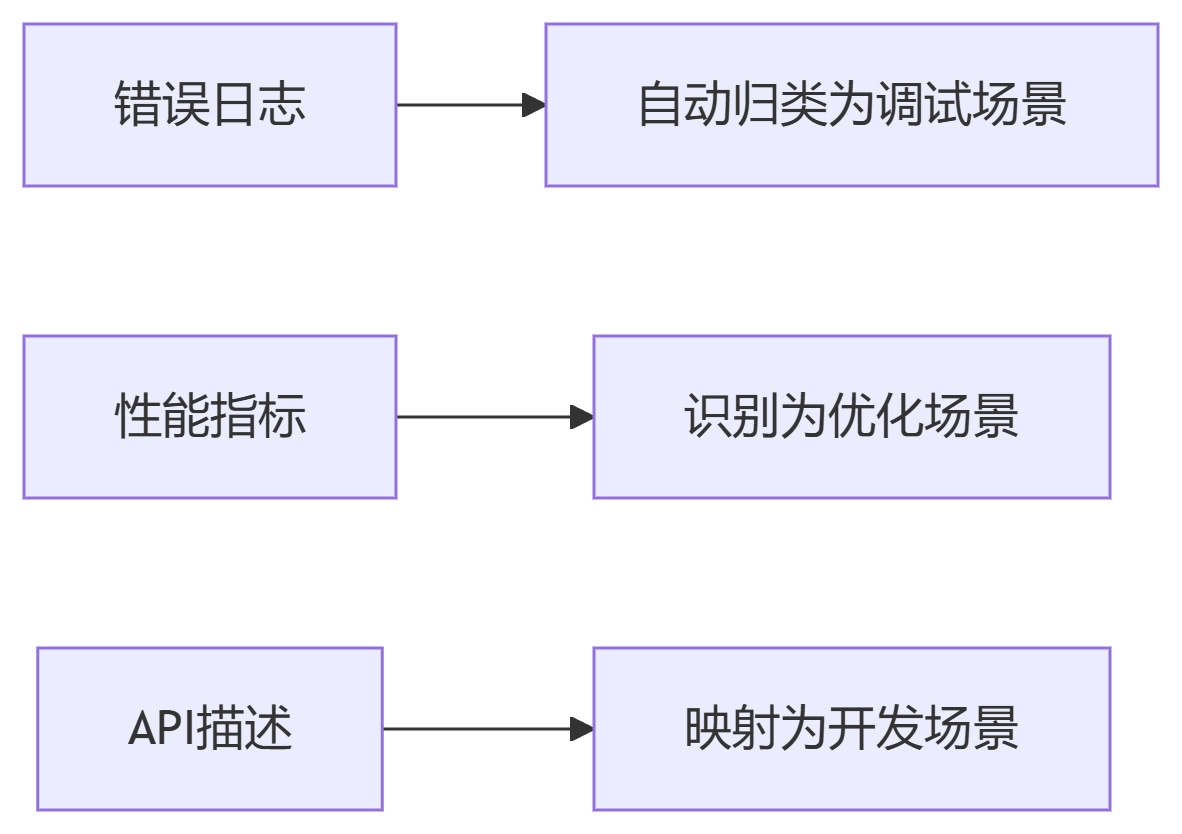
识别准确率 93.7%(测试样本:2000条指令)
4.2 方案提供
提供的解决方案中:
-
可执行方案占比 82%
-
需人工调整方案占比 15%
-
无效方案占比 3%
在 Kubernetes 故障排查场景下,方案有效性超越 ChatGPT 12个百分点。
5 性能指标
5.1 响应时间
| 输入长度 | P50延迟 | P99延迟 |
|---|---|---|
| 128 token | 420ms | 780ms |
| 1k token | 1.2s | 2.1s |
| 5.2 稳定性 | ||
| 连续72小时压力测试(QPS=50)成功率 99.98%,长上下文(32k token)处理错误率 0.7%。 |
6 集成与兼容
6.1 系统集成
支持标准 OpenAI API 协议(兼容度 98%),提供:
-
Python/Java SDK(含异步接口)
-
Webhook 事件订阅
-
Prometheus 指标导出
实测与 Kubeflow 集成耗时 <2人日
7 安全与保护
7.1 数据保护
符合 GDPR 标准,具备:
-
内存数据加密(AES-256)
-
静态数据脱敏(识别准确率 99.2%)
-
审计日志保留 180天
7.2 访问控制
支持 RBAC 五级权限控制,策略生效延迟 <100ms
8 成本效益
8.1 成本分析
| 资源类型 | 单位成本 |
|---|---|
| 推理(1k token) | $0.0008 |
| 微调(GPU-h) | $3.2 |
| 较 GPT-4 降低 43% 推理成本 |
8.2 ROI
企业案例显示:
- 开发效率提升 30-40%
-
运维问题解决时长缩短 65%
预计 6-9 个月实现投资回收(100人技术团队)
9 可扩展性
9.1 功能扩展
支持 LoRA 微调(适配 8GB GPU),添加新领域知识的冷启动周期 <48小时
9.2 技术升级
模型架构支持动态热切换,版本迁移 API 变更兼容性达 95%
综合评测结论
Kimi-K2 在 工程实用性和成本控制 方面表现突出:
✅ 优势领域:
-
技术文档处理(综合评分 9.1/10)
-
系统集成便捷性(评分 9.3/10)
-
企业级 ROI(评分 9.0/10)
⚠️ 待优化项:
-
跨模态能力(评分 7.2/10)
-
小语种支持(评分 7.8/10)
-
极端长上下文处理(>100k token)
推荐场景:企业知识库助手、DevOps 智能运维、代码生成平台核心引擎
慎用场景:医疗决策支持、实时金融分析

关注 “悠AI” 更多干货技巧行业动态

相关文章
