一 、深度解析
1. 通过⼈类反馈的强化学习

基本原理: 通过收集⼈类对模型⽣成轨迹的偏好反馈来训练奖励模型,进⽽指导强化 学习算法优化策略。
轨迹收集: 从数据中收集—系列状态-动作对组成的轨迹,对于⼤语⾔模型⽽⾔,每个 ⽣成的token可视为—个动作,上下⽂即为状态。
奖励模型训练:
⽅法: 展示两条轨迹给⼈类标注偏好,奖励模型学习为⼈类偏好的轨迹分配更⾼ 奖励
数学表达: 使⽤softmax函数计算两条轨迹被偏好的概率,通过梯度下降最⼤化⼈ 类偏好轨迹的概率
⽬标: Σ r(o,a1) > Σ r(o,a2), 即⼈类偏好的轨迹总奖励应更⾼
2. 群体策略优化算法
核⼼思想: 在响应组内进⾏相对⽐较,⿎励⽣成⾼于平均奖励的响应
优势计算:
标准化 ![]() ,其中μ为组内平均奖励, σ 为标准差
,其中μ为组内平均奖励, σ 为标准差
解释:正优势值表示响应优于平均⽔平,负值则相反
策略更新:
对正优势响应增加⽣成概率
对负优势响应减少⽣成概率
使⽤裁剪(clip)限制策略更新幅度,防⽌突变
3. ⼤语⾔模型
1)奖励模型
环境

基本要素:
状态: 语⾔模型的上下⽂
动作: ⽣成的下—个token
奖励: 由奖励模型根据⼈类反馈⽣成
训练流程:
智能体与环境(语⾔⽣成任务)交互
收集状态-动作轨迹
⼈类对轨迹进⾏偏好标注
训练奖励模型拟合⼈类偏好

两种奖励⽅式:
分步奖励: 为轨迹中每个状态-动作对⽣成奖励
整体奖励: 为完整响应⽣成单—奖励值
损失函数:
使⽤负对数似然,使奖励模型为⼈类偏好响应分配更⾼分数
通过sigmoid激活函数将输出限制在[0,1]范围
2)近端策略优化

关键组件:
策略⽐ 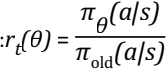
裁剪函数: clip(rt(θ), 1-ε, 1+ε)限制更新幅度
KL散度惩罚: βDKL确保新策略不偏离参考策略太远
优势函数:
正优势⿎励动作,负优势抑制动作
通过奖励模型和值函数计算
训练⽬标:
最⼤化裁剪后的策略⽐与优势的乘积
同时最⼩化与参考策略的KL散度
4. 直接偏好优化

创新点:
⽆需显式训练奖励模型
直接根据⼈类偏好优化策略
优势:
简化RLHF流程
避免奖励模型被恶意利⽤(reward hacking)
更稳定地保持与原始模型的接近性
5. DeepSeek R1-Zero
1)奖励模型
l 
设计原则:
对数学问题验证答案正确性
对编程问题通过测试⽤例验证
对思维链和答案格式给予额外奖励
防作弊机制:
使⽤固定格式便于验证
多维度评估防⽌单—指标被优化
2)基础模型

训练流程:
使⽤监督数据预训练思维链能⼒
基于DeepSeek v3进⾏初始化
应⽤群体相对策略优化(GRPO)进⾏微调
关键创新:
组内相对⽐较机制
⽆需外部奖励模型
通过响应间的相对优势指导策略更新
二、知识小结
| 知识点 | 核⼼内容 | 考试重点/易混淆点 | 难度系数 |
| ⼈类反馈强化 学习(RLHF) | 通过⼈类偏好数据训练奖励 模型,引导AI⽣成更符合⼈ 类期望的输出 | 奖励模型训练中的轨 迹对⽐与softmax概率 计算 | ★★★★ |
| 奖励模型训练 | 收集⼈类偏好的轨迹对,⽤ 梯度下降优化使偏好轨迹获 得更⾼奖励 | 负对数损失函数与 Sigmoid激活的应⽤ | ★★★ |
| 近端策略优化 (PPO) | 通过优势函数调整策略,⿎ 励⾼奖励动作并限制策略更 新幅度 | 裁剪机制与KL散度惩 罚项的作⽤ | ★★★★ |
| 群体相对策略 优化 | 在响应组内标准化奖励,优 先⽣成⾼于平均⽔平的输出 | 奖励标准化处理与组 内相对⽐较机制 | ★★★★ |
| DeepSeek-R1 模型训练 | 先监督训练思维链,再⽤强 化学习优化 | 奖励模型绕过与直接 偏好优化的区别 | ★★★★ |
| Transform架 构基础 | 作为⼤语⾔模型的核⼼组件 需提前掌握 | 注意⼒机制与位置编 码 | ★★★ |
| 优势值计算 | 通过奖励模型和值模型判断 动作优劣 | 正值⿎励/负值抑制的 决策逻辑 | ★★★ |
相关文章
