一 、深度解析DeepSeek V3
1. DeepSeek V3 的成本和效率

训练成本优势: 每万亿tokens仅需180K H800 GPU⼩时,按$2/GPU⼩时计算,总训练成 本557.6万美元(约4000万⼈⺠币),远低于⾏业平均⽔平。
参数效率设计: 采⽤671B参数的混合专家(MoE)架构,但每个token仅激活37B参数,实 际计算量仅为总参数的5.5%。
训练数据规模: 在14.8T⾼质量token上完成训练,其中预训练成本占⽐最⾼( 5.328M) ,上下文扩展(0.238M)和后训练($0.01M)成本显著降低。
2. DeepSeek V3的性能

性价⽐突破: 使⽤阉割版H800显卡(⾮顶级H100)取得SOTA效果,打破”必须堆算⼒ ” 的⾏业认知,实现”中等⼒⽓出奇迹”的效果。
⾏业影响 : 该突破直接影响了英伟达股价,证明通过⼯程优化可降低对⾼端显卡的依 赖。
研发背景: 由量化交易公司幻⽅(⾮传统互联⽹公司)研发,将⾦融领域的⾼效计算 经验迁移⾄AI领域。
3. DeepSeek V3的训练特点
1)⾸个使⽤FP8混合精度训练的⼤号MoE模型

技术领先性: 在开源社区⾸个实现FP8混合精度训练,早于英伟达官⽅对该技术的商⽤ 化进度。
⼯程价值: 将理论探索直接落地,验证FP8作为未来训练数据格式的可⾏性,相⽐传统 FP16/FP32显著降低显存占⽤。
架构选择: 延续LLaMA和GPT-4验证过的MoE架构,平衡模型容量与实际计算开销。
2) 16路流⽔线并⾏(Chimera)
⽓泡优化: 采⽤Chimera技术将流⽔线并⾏的空闲等待时间最⼩化,相⽐传统⽅法提升 约30%训练效率。
⼯程考量: 特别针对⼤规模MoE模型设计,解决专家分布式部署时的负载不均衡问题。
3)数据并⾏(ZeRO1)
内存优化: 通过ZeRO1策略实现显存⾼效利⽤,⽀持在有限硬件资源下训练超⼤规模模 型。
组合策略: 与专家并⾏、流⽔线并⾏形成三维并⾏⽅案,总并⾏度达64 × 16 × N(数据 并⾏维度)。
4)每个token激活4个节点上的专家,减半跨节点通信量
通信优化: 精⼼设计专家路由策略,使每个token仅需访问4个计算节点(⽽⾮全部64 个),将跨节点通信量降低50%。
⼯程启示: 该优化证明分布式训练中通信效率可能⽐计算效率更关键,为⼤数据开发 者转向AI领域提供技术切⼊点。

⻓⽂本突破: 通过两阶段扩展训练(4K→32K→ 128K),在”Needle InA HayStack”测试中 保持全上下⽂窗⼝的稳定性能。
实⽤价值: 突破传统⻓⽂本模型”后半段质量下降” 的局限,实现真正的128K可⽤上下 ⽂,⽽⾮理论⽀持。
4. 推理部署
1)推理部署

PD分离: DeepSeek-V3采取PD分离的⽅式,分别应对prefill和decode两阶段的挑战。
Prefill阶段: 使⽤32个GPU, attention模块采⽤4路张量并⾏+8路数据并⾏, MOE模块采 ⽤32路专家并⾏。
Decode阶段: 使⽤320个GPU,采取320路专家并⾏(256个⼩专家+64个热点专家),有效 降低解码时延,并缓解负载不均衡的问题。
2)推理部署⼆
l 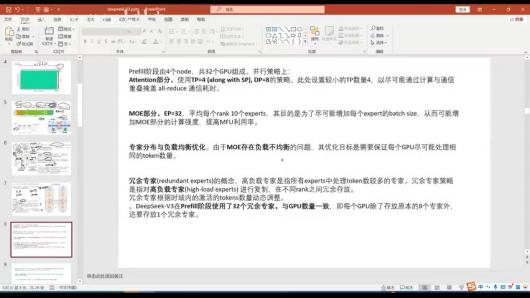
Prefill阶段并⾏策略:
Attention部分: TP=4(along with SP), DP=8。设置较⼩的TP数量4,以尽可能通过计 算与通信重叠掩盖all-reduce通信耗时。
MOE部分: EP=32,平均每个rank 10个experts,⽬的是尽可能增加每个expert的 batch size,提⾼MFU利⽤率。

冗余专家策略: 对⾼负载专家进⾏复制,在不同rank之间冗余存放,根据时域内的激活 的tokens数量动态调整。DeepSeek-V3在Prefill阶段使⽤了32个冗余专家。
Decode阶段并⾏策略:
Attention部分: TP=4(along with SP), DP=80。
MOE部分: EP=320。其中256个GPU每个rank保留—个专家, 64个GPU负责冗余专 家和shared专家。
专家分布与负载均衡优化: 冗余专家的选择策略与prefill阶段—致,也是根据时域内的 激活的tokens数量动态调整。
5. 主要创新点
l 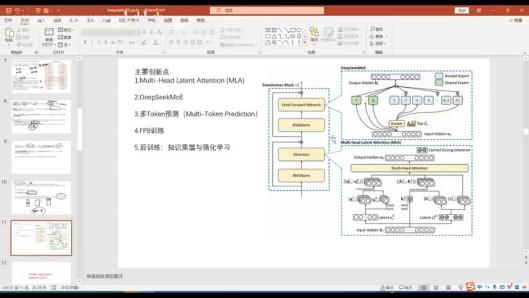
Multi-Head Latent Attention (MLA): ⼩⽶罗浮⼒搞出来的东⻄,是DeepSeek V3的主要贡 献之—。
DeepSeek MoE Feed-forward Network: 个⼈认为是MOE的—个⼯程化版本。
多Token预测: 也是—个⽐较⼤的创新,去年六七⽉份新出的技术。
FP8训练: ⾸创,⽤于提⾼训练效率。
这四个技术不仅适⽤于DeepSeek V3,未来通讯领域的下—代模型也可能逐渐采⽤这些 技术。
6. DeepSeek V3的主要创新点
1) Multi-Head Latent Attention

l MLA技术概述
MLA开发者: MLA是由罗福利开发的。
开发者背景: 罗福利是中国⼈,与苏建林—样,都是相对年轻的开发者(⼤约出 ⽣于1993-1994年)。
技术特点: 罗福利的技术虽然很厉害,但相较于苏建林的旋转位置编码技术, MLA 更多是在现有技术基础上的改造,⽽苏建林的技术则是从零到—的原创,且通⽤ 性极强。
应⽤场景: MLA技术主要⽤于解决模型推理时显存占⽤⼤的问题,特别是在使⽤多 头注意⼒机制的情况下。

MLA与MHA 、GQA 、MQA的⽐较
显存占⽤ :
MHA: 每个token缓存需要2nhdhl的显存。
GQA: 通过压缩技术减少显存占⽤,但效果有所折扣。
MQA: 更极端的⽅法,将多个压缩成—个,显存占⽤进—步减少,但效果折 损更⼤。
MLA: 既能保证效果,⼜能显著降低显存占⽤。
性能⽐较: MHA> GQA> MQA, MLA在性能和显存占⽤之间找到了—个平衡点。
MLA 的计算过程

Query侧:
输⼊向量ht通过WDQ变换成多抽头向量c。
加上旋转位置编码特征,组合成qt。
Key和Value侧:
输⼊向量ht通过WDKV变换,再进⾏压缩和旋转位置编码操作,⽣成kt和vt。
相似度计算:
Query和Key计算相似度,通过加权求和得到Attention输出。
缓存内容:
MLA只缓存压缩后的内容,显著减少显存占⽤。
MLA的显存优化

显存占⽤减少:
通过压缩技术, MLA将每个token的显存占⽤从2nhdhl降低到约4 .5dhl。
计算量优化:
虽然MLA引⼊了额外的矩阵乘法,但可以通过预计算合并矩阵,实际计算量 增加不⼤。
技术来源:
MLA的显存优化技术部分来源于之前的技术,但进⾏了更多的⼯程优化。
其他优化:
MLA还结合了DC的MoE( Mixture of Experts)技术,进—步提升性能。
2) DeepSeekMoE
l 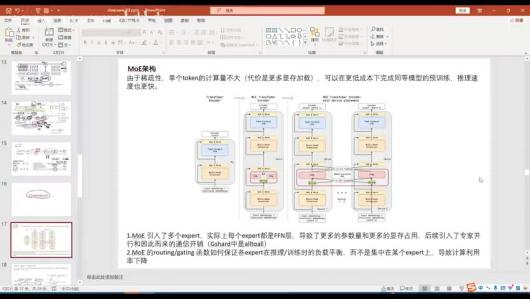
MoE架构特点: 由于稀疏性,单个token的计算量不⼤,可以在更低成本下完成同等模 型的预训练,推理速度更快。但引⼊了多个expert( FFN层),导致参数量和显存占⽤ 增加,同时引⼊了专家并⾏和通信开销。
优化⽬标: 降低通信次数,提⾼计算利⽤率;保证各expert在推理/训练时的负载平 衡,避免集中在某个expert上导致计算利⽤率下降。
3)路由策略
专家数量与任务覆盖类型
专家数量与覆盖任务类型关系: —共E个专家,可以⽐较好覆盖的任务类型只有E 种。如果每次可以路由N个专家,那么可以覆盖的任务类型就包括CEN种。
具体数量: Nr(可路由的专家数量)=256, Ns(通⽤专家数量)=64,总专家数量 =320。
专家激活⽅案
激活⽅案: 每次激活top k的专家,例如可以激活四个左右的专家。
得分计算与BI动态调整
得分计算:通过计算专家向量与输⼊的乘积来得到专家契合度得分。
BI动态调整: 引⼊BI来动态调整得分,如果某些专家在训练时经常不被激活,则稍 微调⼤BI,使其也能参与进激活中。但BI只在选择专家时⽤到,不参与权重计
算。
负载均衡策略介绍
负载均衡策略: 为了保证每个专家都能被照顾到,引⼊负载均衡策略。
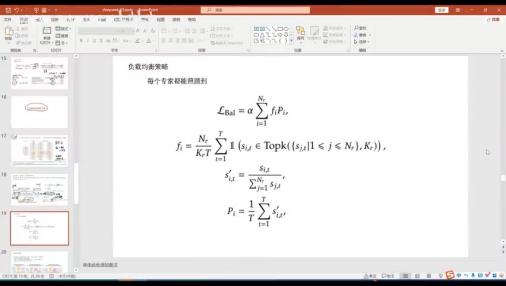 l 负载策略的作⽤与实现
l 负载策略的作⽤与实现
作⽤ : 降低经常被激活的专家的下次被选中的概率,保证训练时各专家都能被均 匀激活。
实现: 在正常的损失函数后⾯新加—个辅助损失,即负载策略。通过计算每个专 家被激活的次数和概率,来调整其在下次被选中的概率,实现负载均衡。其中,
fi表示专家i被激活的次数, Pi表示专家i被激活的概率。辅助损失函数为LBa1 = αΣ i= 1 Nr fiPi,通过优化此损失函数来实现负载均衡。
4)丢弃策略
l 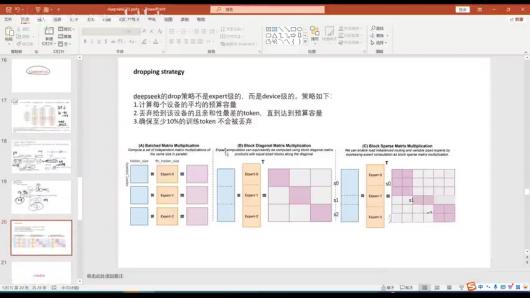 l 丢弃策略概述
l 丢弃策略概述
设备级策略: DeepSeek的drop策略不是expert级的,⽽是device级的,针对设备进 ⾏token丢弃
核⼼⽬标: 防⽌专家负载过重产⽣⽊桶效应,避免拖慢整个系统
丢弃策略的具体步骤
计算每个设备的平均预算容量
丢弃给到该设备且亲和性最差的token,直到达到预算容量
确保⾄少10%的训练token不会被丢弃
丢弃策略中的专家饱和概念
饱和机制: 每个专家设有token上限,防⽌单个专家处理过多token
负载均衡: 通过丢弃策略实现专家间的负载均衡,避免某些专家过载
丢弃策略中的token上限与丢弃⽐例
上限设置: 在8卡设备上,会丢弃亲和⼒得分最低的token
丢弃限制: 最多丢弃10%的token,保证90%的token能参与训练
专家计算效率的优化⽅法
矩阵合并: 将多个专家(FFN)的矩阵并⾏拼成—个⼤矩阵—次性计算
效率提升: 相⽐逐个专家计算,合并计算能显著提⾼计算效率
丢弃策略中的token数量—致性要求
历史要求: 早期MoE需要保证每个专家对应的token数量相同
⻓度限制: 不同专家处理的token序列⻓度需要—致
硬件突破对丢弃策略的影响
H800⽀持: 新—代硬件(H800)可以⽀持不同⻓度的token序列
计算⾰新: 允许不同⻓度的token序列作为—个整体进⾏预计算
丢弃策略中的稀疏性问题
稀疏计算: 该算法会产⽣⼤量稀疏计算
密度局限: 计算密度不⾼,这是当前策略的—个局限性
5) FP8模型
FP8模型概述

⾸创性: DeepSeek-V3是⾸个开源使⽤FP8技术的模型,开创了8位浮点数训练的先 河
技术背景: 传统训练使⽤FP32或FP16混合精度,存在显存占⽤⼤、通信量⼤、计 算速度慢等问题
 l FP8模型的优势与问题
l FP8模型的优势与问题
三⼤优势:
内存节约: 显存占⽤量显著减少
通信优化: 减少数据传输量
计算加速: 低精度运算速度更快
核⼼问题:
精度不⾜: 模型训练后期梯度变化微⼩,低精度易导致四舍五⼊误差
量化误差: 粗粒度量化会因异常值增加误差
FP8的两种类型: E4M3与E5M2
E4M3格式:
结构: 4位指数+3位尾数
特点: 数值更精确但动态范围较⼩
E5M2格式:
结构: 5位指数+2位尾数
特点: 动态范围较⼤但精度较差
硬件⽀持: 英伟达H800 、H100 、4090等显卡均⽀持这两种格式

DeepSeek V3中的FP8训练
统一格式: 全程使⽤E4M3格式保持数值精确性
混合精度:
前向传播:输⼊转FP8与权重矩阵乘法,结果⽤FP32保存
反向传播:梯度计算使⽤ FP8,结果转FP32保存
创新设计: 采⽤细粒度per-tile(1×128)和per-group(128×128)量化降低误差
FP32转FP8的步骤

两步转换:
缩放: Unscaled FP32 = FP32 / scale
转换: FP8 = Convert(Unscaled FP32)
示例: 数组[1000.0,23.0,123.123]除以scale=1000.0/448进⾏压缩
原理: 通过等⽐映射将FP32数值范围压缩到FP8可表示范围内
FP8的量化⽅式

量化粒度:
- per-tensor: 整个张量统—量化(误差最⼤)
- per-token: 按token单独量化
- group-wise: 将token分段量化
- tile-wise: 按区域块量化
- 精度权衡: 量化区间越细精度越⾼,但计算复杂度也越⾼
- 实例说明: 向量[0.1,0.2,100,200]整体量化会丢失⼩数值信息,分段量化可保留区 分度
FP8矩阵乘法与量化操作

操作流程:
- 将输⼊向量和权重矩阵均分128⼤⼩的块
- 每块使⽤独⽴scale因⼦进⾏量化
- 量化后的FP8块进⾏矩阵乘法
- 结果乘回scale因⼦解量化
计算优化: 在Tensor Core上执⾏1× 128与128× 128的FP8矩阵乘
FP8加法中的精度损失问题
- 典型问题: 如0.0013+0.001在两位精度下会丢失0.0003
- 影响: 训练后期梯度变化微⼩,精度不⾜会导致参数停⽌更新
- 根本原因: 低精度浮点数的有效位数有限,⼩数位易被截断
l DeepSeek在FP8加法中的处理

分段累加:
- 先⽤FP8累加4次中间结果(如C1到C4)
- 将FP8中间结果转FP32再进⾏最终累加
创新点: ⾸次开源这种混合精度累加⽅法
优势: 平衡计算效率与精度,避免纯FP32计算带来的过重负担
6)内容总结
l 
三⼤创新:
- MoE技术: 提⾼推理速度,降低成本(每次仅激活37B参数)
- MLA架构: 减少KV缓存压⼒
- FP8训练: ⾸家开源⽅案,显著降低训练成本
成本优势: 每万亿token训练仅需180K H800 GPU⼩时,总成本约557.6万美元
设计理念: 在算⼒受限条件下追求成本与效率的最佳平衡
7. 总结
1) FP8技术优势

计算速度: FP8 Tensor Cores⽐16-bit Tensor Cores快2倍
内存优化: 减少memory movement,提升数据传输效率
部署便利: 若模型已在FP8中训练,部署更加⽅便
动态范围: FP8拥有更宽的动态范围
转换效率: FP8到FP16/FP32/BF16的转换电路设计更简单直接,相⽐INT8/UINT8到FP的 转换节省了乘法和加法运算开销
2)混合精度训练
后续课程: 将专⻔安排课程讲解FP8格式及混合精度运算
参考资料: 可通过助理⽼师获取相关公开课视频,或在B站搜索观看
3) DeepSeek-V3核⼼技术

模型规模: 总参数671B,每个token激活37B参数 l 关键技术:
- MoE架构: 提⾼推理速度,降低成本
- MLA技术: 减少缓存压⼒
- FP8应⽤: 开源第—家降低训练成本
- 硬件配置: 推理使⽤320卡36B配置
4)混合精度训练框架

量化策略: 采⽤细粒度量化策略,包括1 × N元素分组或块状分组
存储优化: 在训练过程中缓存和分发FP8激活值,同时以BF16存储低精度优化器状态 l 验证范围: 在DeepSeek-V2-like和RepsnokV2模型上验证了FP8混合精度训练框架
5)评估框架

评估基准:
- 多学科选择题: MMLU系列、C-Eval 、CMMLU等
- 语⾔理解推理: HellaSwag 、PIQA 、ARC等
- 闭卷问答: TriviaQA 、NaturalQuestions
- 阅读理解: RACE 、DROP 、C3等
- 数学能⼒ : GSMSK 、MATH 、MGSM等
- 编程能⼒ : HumanEval 、LiveCodeBench等
评估⽅法: 采⽤困惑度评估和⽣成式评估两种⽅式
二、知识小结
| 知识点 | 核⼼内容 | 技术亮点/创新点 | 应⽤价值 |
| DeepSeek V3 模型特点 | 国内最优秀的开 源模型,成本与 效果平衡突出 | 训练成本仅5500万美元, 推理时仅激活37B参数 | 降低⼤模型训练 ⻔槛,提升商业 化可⾏性 |
| 模型架构创 新 | 采⽤混合专家模 型(MoE)设计 | 671B总参数仅激活
37B, 64路专家并⾏+16路 流⽔并⾏ |
实现⾼参数规模 下的⾼效推理 |
| 训练技术创 新 | ⾸创FP8混合精度 训练⽅案 | E4M3格式全程应⽤,计 算-存储分离优化 | 训练效率提升
30%+,显存占⽤ 减少50% |
| 注意⼒机制 优化 | 多抽头潜在注意 ⼒(MLA)技术 | 显存占⽤降⾄4.5DHL(原 2nhDHL) | ⻓⽂本处理能⼒ 突破, 128k上下 ⽂保持稳定 |
| 推理架构设 计 | 预计算(pro)与解 码(decode)分离 | 32卡pro阶段+320卡 decode阶段流⽔线 | 吞吐量提升5
倍, TTFT指标优化 |
| ⼯程优化策 略 | 动态专家负载均 衡机制 | 冗余专家副本+亲和⼒得 分调整 | 通信成本降低
60%,集群利⽤率 达90%+ |
| 硬件适配⽅ 案 | 基于阉割版H800 显卡开发 | 未使⽤H100即实现SOTA 效果 | 突破算⼒封锁, 国产化适配性强 |
| ⾏业影响分 析 | 打破”⼤⼒出奇迹 “范式 | 中等算⼒出顶级效果(四 两拨千⽄) | 导致英伟达股价 波动,改变⾏业 研发⽅向 |

相关文章
