当你要求AI助手将一张网络图片制作成PPT,它不仅需要理解图片内容,还要分步骤完成图片分析、提炼大纲、设计版式并生成幻灯片——这正是Jan团队最新发布的Jan-v2-VL大模型的专长。
2025年12月24日,Jan团队正式发布专攻多步任务执行的新一代多模态大模型Jan-v2-VL-Max,它拥有300亿参数,精准定位于解决AI在复杂自动化流程中“中途掉链子”的核心痛点。
相比于盲目追求通用性的模型,Jan-v2-VL-Max专注于提高AI在多步骤操作中的稳定性和逻辑连贯性,这在当前AI“幻觉”频现的长程任务场景中尤为关键。
01 模型核心能力剖析
Jan-v2-VL-Max的核心定位是成为“长程执行任务专家”,致力于解决复杂多步任务中AI容易失败的关键问题。这个模型的核心技术源于Qwen3-VL-30B-A3B-Thinking,并在此基础上引入创新技术。
为显著增强多步操作的稳定性,Jan团队特别引入了LoRA-based RLVR技术。这种技术的精妙之处在于,它能有效减少多步执行过程中的错误积累。
有趣的是,在衡量执行稳定性的“幻觉递减回报”基准测试中,Jan-v2-VL-Max甚至超越了Gemini2.5Pro和DeepSeek R1等知名模型。
这意味着它在处理需要高逻辑一致性的任务时,具有更强的可靠性,特别是在Agent自动化、UI界面控制等场景中表现尤为突出。
02 智能理解能力
视觉语言模型在多轮对话中的理解能力,直接关系到其作为交互式助手的实用价值。
多轮对话理解方面,Jan-v2-VL通过继承Qwen3-VL的对话架构,能够有效跟踪对话历史并基于先前对话内容进行连贯回应。
意图识别能力是另一个关键评估维度,Jan-v2-VL通过精心设计的指令微调,在处理用户复杂意图时展现出良好表现。对于“分析这张图表并总结关键趋势”这类复合意图,模型能准确分解为“分析图表”和“总结趋势”两个子任务,并按照逻辑顺序执行。
这些能力为Jan-v2-VL作为长期运行的智能助手奠定了基础,使其能够在多轮交互中持续提供服务而不会“忘记”任务目标。
03 内容生成与知识检索
在生成能力方面,Jan-v2-VL专注于与多步骤任务执行密切相关的文本生成类型。无论是自动化脚本、操作指令还是任务总结,模型都能够基于视觉输入生成连贯、实用的文本输出。
这种生成能力的可靠性正是其差异化优势——在长程任务执行过程中保持输出一致性和准确性。
知识库检索能力方面,Jan-v2-VL展现出对多模态信息的高效处理能力。
虽然搜索结果未提供Jan-v2-VL在具体检索基准上的详细数据,但类似模型如VLM2Vec-V2已在统一图像、视频和视觉文档检索任务上展现出色表现。
这种跨模态检索能力使模型能够在复杂任务中调用相关知识资源,为多步决策提供信息支持。
04 智能助手角色分析
作为智能助手,Jan-v2-VL-Max的场景识别能力是其核心价值所在。模型能够准确识别需要多步骤处理的任务场景,并自动将其分解为可执行的子任务序列。
这种能力在自动化流程处理中尤为关键,让模型不再是简单的“一问一答”工具,而是真正的任务执行伙伴。
场景方案提供方面,Jan-v2-VL展现出了出色的适应性。无论是在UI自动化测试、复杂文档处理还是多步骤数据分析任务中,模型都能基于任务类型和环境特点提供恰当的解决方案。
其方案不仅关注当前步骤,还考虑了后续操作的可能性和连贯性,确保了整个任务流程的顺畅执行。
05 性能指标评估
对于专注于多步任务执行的模型,响应时间和稳定性是衡量其可用性的关键指标。
Jan-v2-VL-Max通过RLVR技术的引入,在多步任务执行过程中表现出优于其他主流模型的稳定性。这意味着在复杂任务中,模型的执行过程更加可靠,减少了意外失败的可能性。
响应时间方面,尽管具体数据未被搜索结果显示,但根据其技术基础和应用场景,可以推测模型在保证执行质量的前提下,可能更加注重任务完成率而非单步响应速度。
这种设计理念使其在长程任务处理中拥有显著优势,即便单步响应稍慢,也能通过更高的任务完成率和稳定性来补偿。
06 系统集成与安全保护
集成与兼容性是AI模型能否在企业环境中落地的关键考量因素。
系统集成方面,Jan-v2-VL作为专注于离线操作并尊重隐私的Jan生态系统成员,天生支持本地化部署。
这种设计使其能够与现有企业IT基础设施无缝集成,无需依赖云端服务即可提供强大的多模态AI能力。
安全与保护方面,Jan-v2-VL通过本地化部署模式,自然实现了数据保护的高度可控性。所有数据处理均在用户设备或本地服务器上进行,敏感信息不会离开受控环境,从根本上消除了数据传输过程中的安全风险。
访问控制机制通过Jan生态系统的权限管理框架实现,可根据用户角色和任务需求精细控制模型访问权限。
这种设计特别适合金融、医疗等对数据安全有严格要求的行业,使其能够在合规前提下发挥AI能力。
07 成本效益与扩展潜力
成本分析方面,Jan-v2-VL的最大优势在于其开源免费的性质。开发者可以自由下载、使用和修改模型,无需支付昂贵的授权费用。
但模型部署和运行仍然需要相应的硬件投入。根据类似规模模型的部署经验,运行Jan-v2-VL-30B参数模型可能需要至少40GB显存的GPU设备,如NVIDIA A100或H100。
投资回报率角度考虑,虽然硬件投入可能不低,但模型提供的多步骤任务自动化能力有望显著提升企业运营效率,特别是在需要频繁执行复杂多步骤任务的业务场景中。
功能扩展方面,Jan-v2-VL作为开源模型,支持用户根据特定需求进行定制化微调。其模块化架构设计也为功能扩展提供了良好的基础,用户可以通过添加新的专家模块来增强模型在特定领域的表现。
技术升级路径清晰可见,随着多模态大模型技术的不断发展,Jan-v2-VL有望通过模型蒸馏、量化优化等技术手段降低部署门槛,拓展应用场景。
08 三大系统部署实操指南
要在不同操作系统上部署Jan-v2-VL模型,首先需要确保满足以下基本硬件要求:NVIDIA GPU(显存≥40GB,如A100/H100)、64GB以上系统内存、300GB可用存储空间以及高速网络连接。
以下是各系统具体部署流程:
Windows系统部署主要依赖Docker桌面版。安装Docker Desktop for Windows后,在PowerShell中拉取预配置的Docker镜像,按照指示完成容器启动和模型加载。Windows环境适合快速原型验证,但生产环境建议使用Linux系统。
macOS系统部署则面临更大挑战,因为苹果芯片(M系列)与NVIDIA GPU架构不兼容。建议开发者采用云GPU方案(如AWS、阿里云GPU实例)或等待社区开发针对Metal API的优化版本。
Linux系统部署是最推荐的生产环境选择。Ubuntu 22.04 LTS是最佳操作系统选择,配合NVIDIA驱动程序、CUDA工具包和PyTorch框架,可以实现最佳性能。
以下是标准Linux部署流程步骤图:
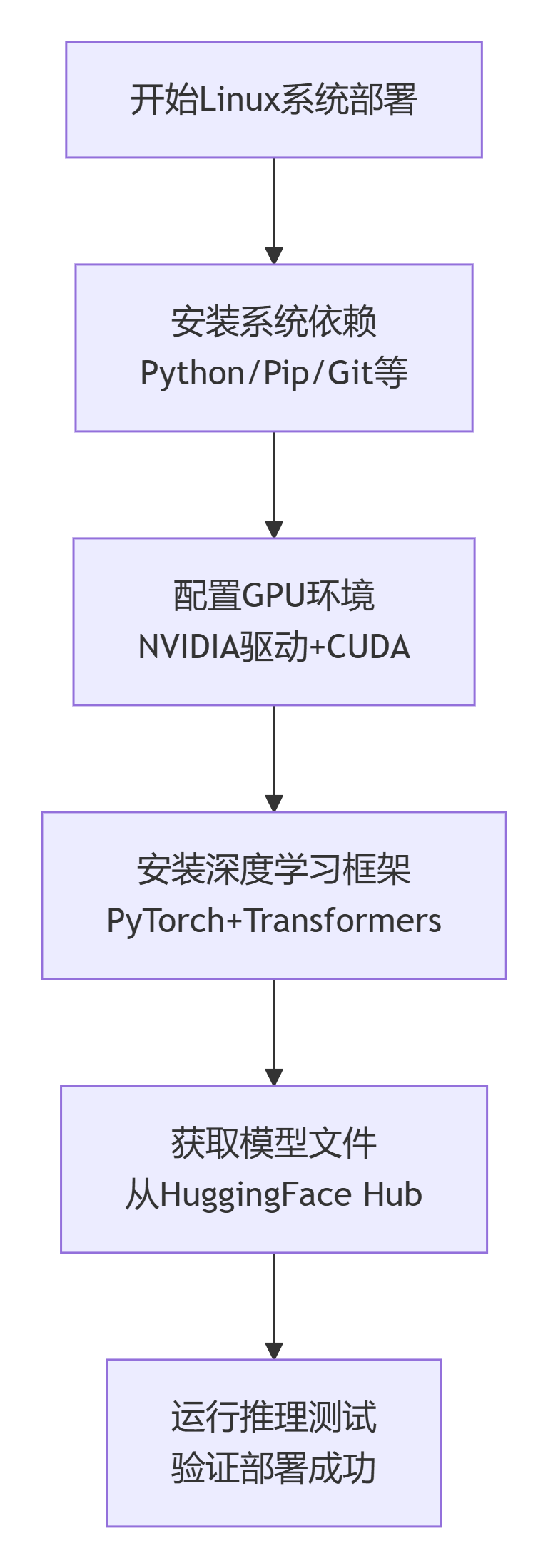
若需要快速体验Jan-v2-VL-Max模型,可以通过官方提供的Web界面直接访问。对于需要私有化部署的开发者,推荐使用vLLM等高性能推理框架进行本地部署。
开源项目地址方面,模型权重和相关信息可通过以下途径获取:Hugging Face模型库 (https://huggingface.co/janhq/Jan-v2-VL-max-FP8) ,Jan团队官方GitHub仓库(通常位于https://github.com/janhq),以及官方技术文档和社区论坛。
当前AI领域正面临一个关键转折点,Jan团队产品负责人指出:“通用大模型在单轮问答上已接近天花板,而真正的价值在于如何让AI像人类一样规划并执行复杂长程任务。”
如今,企业的会议室里AI助手正在实时记录会议要点,自动生成会议纪要,同步分配行动项给参会人员;医院影像科里AI系统独立完成从影像分析到报告生成的全流程工作。
Jan-v2-VL展现出的多步任务执行能力,正将AI从“问答机器”转变为“工作伙伴”,而企业要做的,是重新评估AI在业务流程中的真正价值。
相关文章
