一行代码的合规性检查,揭开了当前所有主流AI编程助手在真实生产环境中高达70%失败率的残酷真相。
2026年1月14日,AI大模型公司MiniMax正式开源了首个面向编程智能体(Coding Agent)的系统性评测集OctoCodingBench。这一基准测试不仅量化了智能体对指令的遵循能力,更揭示了从“能力展示”到“真正干活”之间的巨大鸿沟。
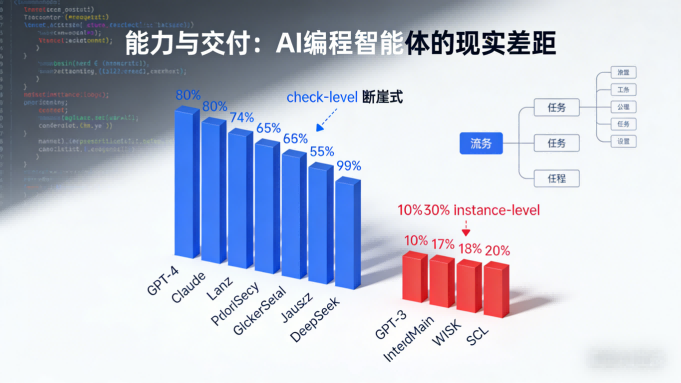
评测结果暴露了行业现状:所有受测模型的Check-level准确率均超过80%,但端到端的Instance-level成功率仅有10%-30%。这意味着模型能在细粒度检查上表现尚可,但在完整任务执行中却屡屡失手。
01 行业痛点
当前的AI编程领域正面临一个尴尬局面。尽管各大模型在单项能力测试中表现亮眼,却在真实生产环境中频频“翻车”。
MiniMax此次开源OctoCodingBench,直指这一核心矛盾。其评测结果显示,随着对话轮次增加,模型指令遵循率呈阶梯式下降,到第五轮后平均衰减约25%。
这个数据揭示了一个关键问题:现有的基准测试如SWE-bench主要关注任务完成度,却忽略了智能体在完成任务过程中是否遵循规则。
02 评测革命
OctoCodingBench标志着编程智能体评估方式的根本转变。这个评测集从七种不同指令来源全面检验智能体的合规表现,包括系统提示、系统提醒、用户查询、项目级约束等。
这一多维评估框架包含72个精选实例和2422个评估检查项。每个实例都模拟了真实开发场景,要求智能体同时应对自然语言查询、项目规范和工具使用协议。
最引人注目的是其二元检查清单评分机制,使得任务完成率与规则遵循率被明确区分。这种设计理念反映了MiniMax对AGI价值评估的新视角——正从模型榜单的“能力上限”转向企业落地的“可交付性”。
03 核心发现
基于OctoCodingBench的广泛评估,MiniMax披露了一系列极具启发性的实验结果。
所有受测模型在细粒度Check-level指标上准确率均突破80%,但端到端Instance-level成功率仅10%-30%,暴露出长链路任务稳定性不足。这暗示着智能体可能在某些步骤上表现正确,却在整体任务执行中失败。
随着对话轮次增加,模型指令遵循能力呈现明显下降趋势。这种“多轮遗忘”现象严重限制了智能体在复杂项目中的实际效用。
研究还发现,开源模型在过程合规指标上正快速逼近甚至超越部分闭源模型。这一发现可能会改变AI编程工具的市场格局,降低企业采用门槛。
04 竞争变局
OctoCodingBench的发布不仅是技术评估工具的创新,更预示着行业竞争要素的转变。在Agent时代,“数据与评测范式的重要性正在上升为新的竞争要素”。
此次评测集的发布恰逢MiniMax完成港股上市后不久,这家被视为“中国版Anthropic”的AI公司,正通过定义标准来巩固其技术领导地位。其2025年前三季度营收同比增长174%的业绩,也为其在这一领域的投入提供了充足底气。
从产业角度看,评测体系本身正在成为AGI时代的重要基础设施。没有统一、贴近真实场景的评估标准,就难以判断模型是否具备规模化部署的条件。
05 现实挑战
MiniMax明确指出,目前尚无模型达到生产级可靠性要求,过程合规与安全性仍属行业盲区。这一判断为整个AI编程领域敲响了警钟。
与上周末AGI Next峰会圆桌嘉宾的观点相呼应,“2026年大模型胜负手在基础设施与训练方法,而非单纯算力堆叠”。当行业开始用生产力而非惊艳度衡量AI,当标准围绕真实工作而非理想任务构建,AGI才真正站在商业化与产业化的门槛上。
OctoCodingBench支持多种脚手架环境,如Claude Code、Kilo和Droid,这些都是实际生产环境中使用的工具。所有测试环境都可以通过公开的Docker镜像进行访问,极大地方便了开发者的使用与测试。
OctoCodingBench数据集已在Hugging Face平台开源,任何开发者都可以访问并基于此基准测试自己的编程智能体。
随着部分开源模型在过程合规指标上快速逼近闭源模型,整个行业正面临价值重估。企业将不再仅仅关注模型的参数规模或单项能力得分,而是更加重视其在真实工作场景中的“可交付性”。
当一行代码的合规性成为衡量AI生产力的新标准,编程智能体的竞争才刚刚进入深水区。这场由MiniMax率先发起的评测革命,或许正是AGI从实验室走向生产环境的关键转折点。

关注 “悠AI” 更多干货技巧行业动态
相关文章
