在移动端运行大模型已不再是新鲜事,但让浏览器具备强悍的 AI 处理能力正成为新的技术趋势。近日,开发者通过引入 Google 最新的 TurboQuant 算法,成功将 Gemma4模型搬进了浏览器。这意味着用户无需配置复杂的 API 环境,也不必支付任何订阅费用,就能在本地环境下实现流畅的 AI 交互。
此次技术突破的核心在于 Google 研发的 TurboQuant 算法。它主要针对大模型的“临时记忆库”——KV Cache(键值缓存)进行了深度优化。
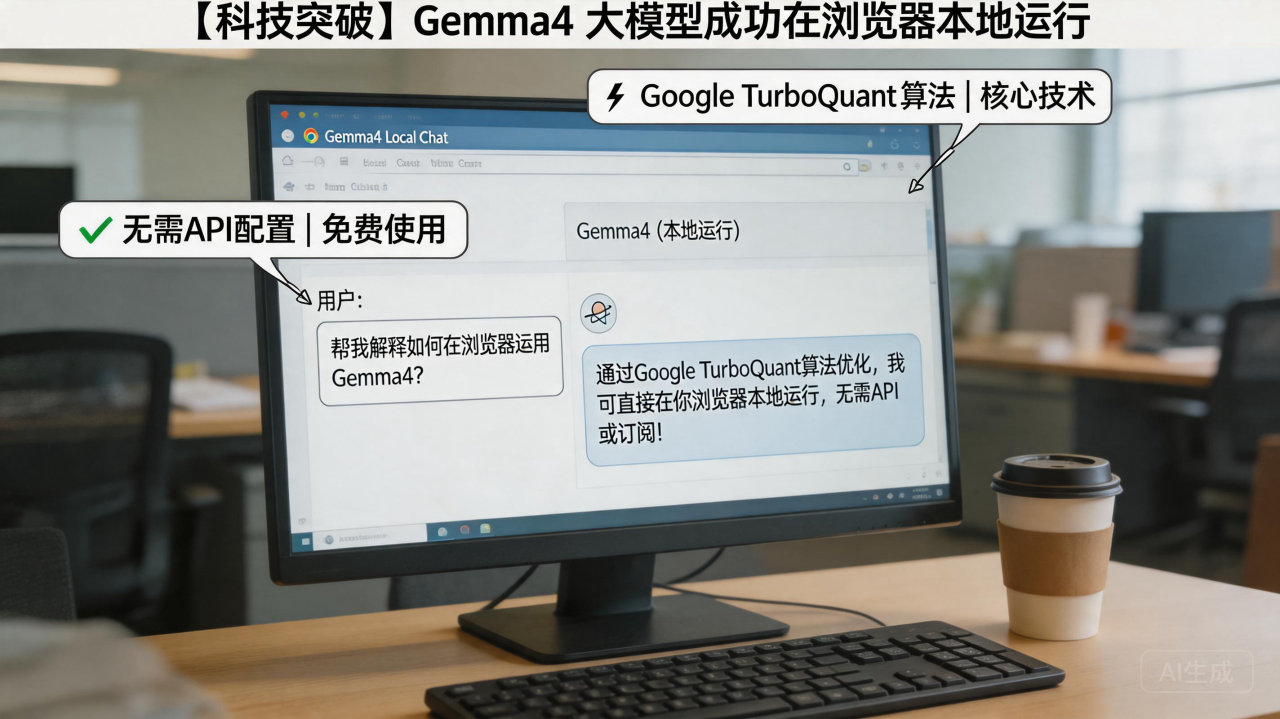
在传统模式下,模型在处理长对话或复杂任务时,缓存数据会迅速膨胀,导致系统卡顿。而 TurboQuant 能够将这些向量数据压缩至原来的六分之一,且支持在压缩状态下直接进行检索。这种“不解压直接搜”的特性,不仅让模型能够记住更长的上下文内容,还显著提升了计算效率。
以集成了该技术的本地化绘图工具为例,用户只需在支持 WebGPU 的 Chrome134+ 桌面浏览器中打开网页,即可调用 Gemma4E2B 模型。
在实际测试中,生成一张结构完整的 Excalidraw 流程图仅需约32.9秒。数据显示,该模型在浏览器中的生成速度约为每秒24个 token,端到端响应灵敏。最显著的优势在于,由于整个运算过程完全在用户本地设备上完成,不消耗任何在线 Token,实现了真正意义上的“创作零成本”。
尽管实现了“流量自由”,但本地运行仍有一定的硬件门槛。用户首次使用需要下载约3.1GB 的模型文件,且对浏览器的版本有明确要求。
这种基于 WASM(WebAssembly)和 TurboQuant 的方案,为轻量级 AI 应用提供了一个极具参考价值的范本。它证明了在不依赖高昂云端算力的情况下,通过算法优化,浏览器同样可以胜任复杂的流程图绘制与长文本处理任务。对于追求隐私安全与成本控制的用户而言,这种“即开即用、本地运行”的模式或将成为未来 AI 工具的主流形态。
Moonshot AI与清华大学提出预填充即服务(PrfaaS)新架构,旨在解决大型语言模型推理中计算资源瓶颈。该架构将高计算密集的预填充阶段(生成键值缓存)与解码阶段分离,以优化资源利用,突破传统服务限制。
谷歌发布Gemma4系列开源模型,实现AI能力轻量化突破。其中一款仅激活3.8亿参数,性能却超越参数规模20倍的大型模型,使强大AI可轻松部署于手机和轻薄笔记本。该系列包含2.3B和4.5B等不同参数规模的模型,推动人工智能服务更便捷普及。
谷歌在iOS平台推出实验性语音输入应用“Google AI Edge Eloquent”,主打离线优先和智能润色功能,利用边缘AI技术将口语实时转化为专业文本。此举标志着谷歌进入高端AI语音转文字市场,与Wispr Flow和SuperWhisper竞争。应用搭载Gemma4系列技术,强调实时处理和文本优化能力。
谷歌DeepMind发布新一代开源模型Gemma4,性能实现代际跨越,并将许可证改为Apache2.0,方便开发者商用和二次开发。此次推出四款不同规格模型,覆盖从手机端到工作站的全场景需求。
谷歌发布新一代开源AI模型Gemma4,采用Apache2.0许可证,取代以往限制性协议,允许开发者自由使用、修改和分发,便于商业化应用。该模型在技术架构上实现性能与生态兼容性双重升级。

关注 “悠AI” 更多干货技巧行业动态
相关文章
