1200万语音文本对齐数据、1350万指令样本、20项任务全覆盖——LLaSO框架正在开启语音AI的透明化、可复现研究新时代。
北京深度逻辑智能科技有限公司(LogicAI)近日发布了全球首个完全开源的语音语言模型(LSLM)研究框架LLaSO(Large Language and Speech Model)。
这一突破性技术为解决语音AI领域长期存在的碎片化、数据不透明和评估标准缺失等问题提供了全新解决方案,被誉为语音AI领域的“ImageNet时刻”。
01 语音AI发展困境
在大型语言模型(LLM)与视觉语言模型(LVLM)飞速发展的今天,语音语言模型(LSLM)的发展却相对滞后。该领域长期面临四大核心挑战。
架构路径分化严重,不同技术方案难以直接比较;训练数据私有化,主流模型依赖不透明数据;任务覆盖局限,副语言学信息处理不足;交互模态单一,缺乏复杂模态组合支持。
这些问题严重阻碍了技术的可复现性和社区的系统性进步。许多研究虽然发布模型权重,但训练数据和配置细节常常被“雪藏”起来。
02 LLaSO解决方案
LLaSO框架通过三大核心开源组件构建完整生态体系。LLaSO-Align数据集提供1200万语音-文本对齐样本,通过自动语音识别技术建立精确的跨模态对齐。
LLaSO-Instruct包含1350万指令样本,覆盖语言学、语义学和副语言学三大类20项任务。它系统性支持三种交互配置:文本指令+音频输入、音频指令+文本输入和纯音频交互。
LLaSO-Eval评估基准包含15,044个测试样本,覆盖全部20项任务,确保评估公平性和可复现性。
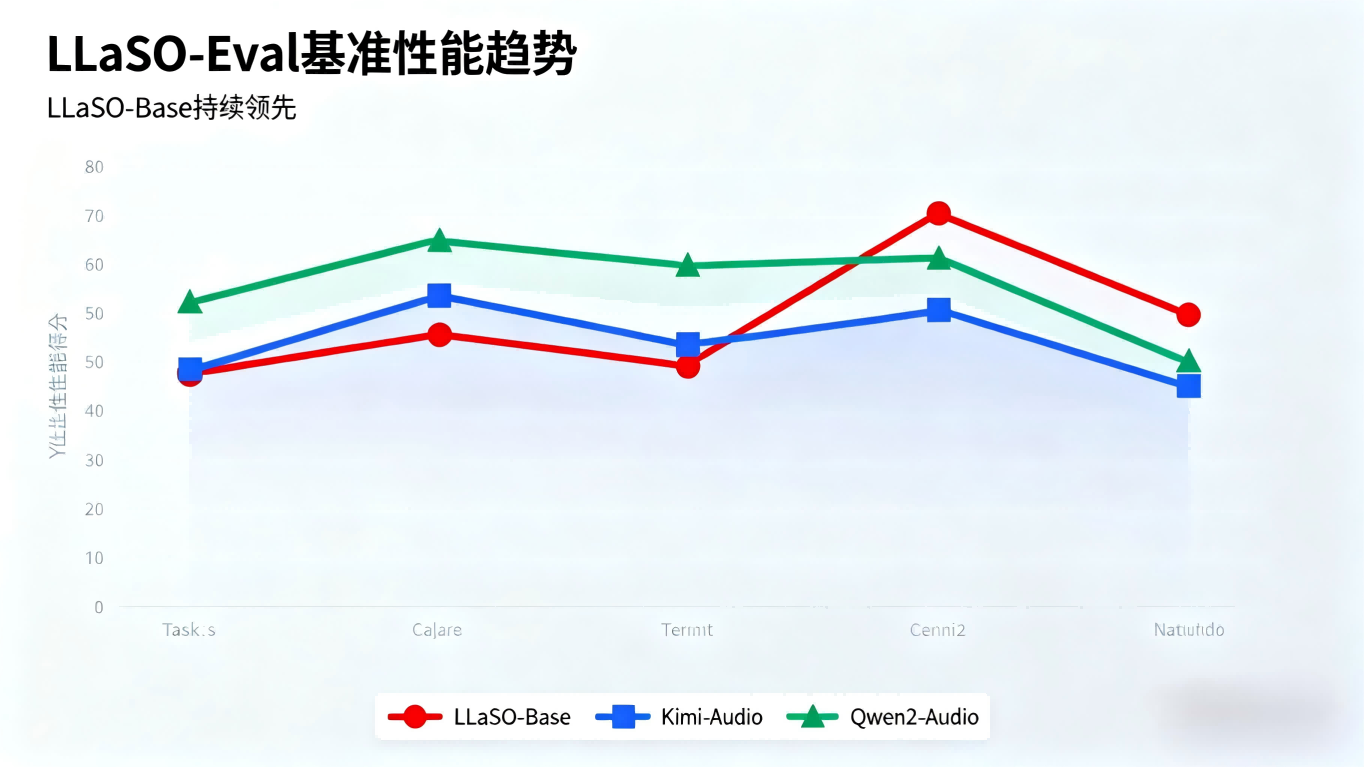
03 技术验证成果
为验证框架有效性,逻辑智能团队开发了38亿参数的LLaSO-Base参考模型。模型采用三阶段架构:Whisper-large-v3语音编码器、多层感知机模态投影器和Llama-3.2-3B-Instruct语言模型骨干网。
实验结果显示,LLaSO-Base在标准化评估中取得了0.72的综合得分,显著优于Kimi-Audio(0.65)和Qwen2-Audio(0.57)等竞争模型。
在自动语音识别任务中,该模型词错误率和字错误率分别低至0.08和0.03,展现出惊人的语音转录精度。在副语言学任务上,它也展示出对说话人特征和语音内容的深刻理解能力。
04 开源策略影响
LLaSO的开源策略为语音AI领域带来革命性变化。它降低了研究门槛,使研究者能够专注于算法创新而非数据收集。
该框架为LSLM领域建立了统一技术标准,提供可复现性基础和公平比较基准,加速技术积累。
对于工业应用而言,LLaSO框架降低了开发成本和技术风险,为定制化开发和生态系统建设提供了坚实基础。智能助手、语音翻译、智能家居等领域将直接受益于这一开源创新。
随着LLaSO框架的广泛采用,全球开发者和研究者将能够站在统一、透明的技术基础上共同探索语音AI的无限可能性。
逻辑智能CEO表示,他们计划举办一系列研讨会和开发者活动,促进社区交流与合作。这个开源项目不仅是一次技术创新,更是对整个语音AI领域的革命性推动,预示着一个更加智能化的未来即将来临。

关注 “悠AI” 更多干货技巧行业动态
相关文章
