机器人缓缓伸出手臂,在充满透明玻璃杯和反光金属的复杂环境中,精准抓取目标物体——这一幕背后,是一个刚刚开源的“通用大脑”在指挥着它的每一个动作。
2026年1月27日,继前一日开源高精度空间感知模型后,蚂蚁集团旗下灵波科技宣布全面开源其具身大模型 LingBot-VLA。
这一面向真实机器人操作场景的“智能基座”实现了跨本体、跨任务泛化能力,并大幅降低后训练成本。
01 技术突破
具身智能领域长期面临一个根本性挑战:如何让同一套智能系统适应不同形态的机器人硬件和多样化的任务需求。
传统方法需要为每种机器人和每个任务单独收集海量数据并训练模型,成本高昂且难以规模化。
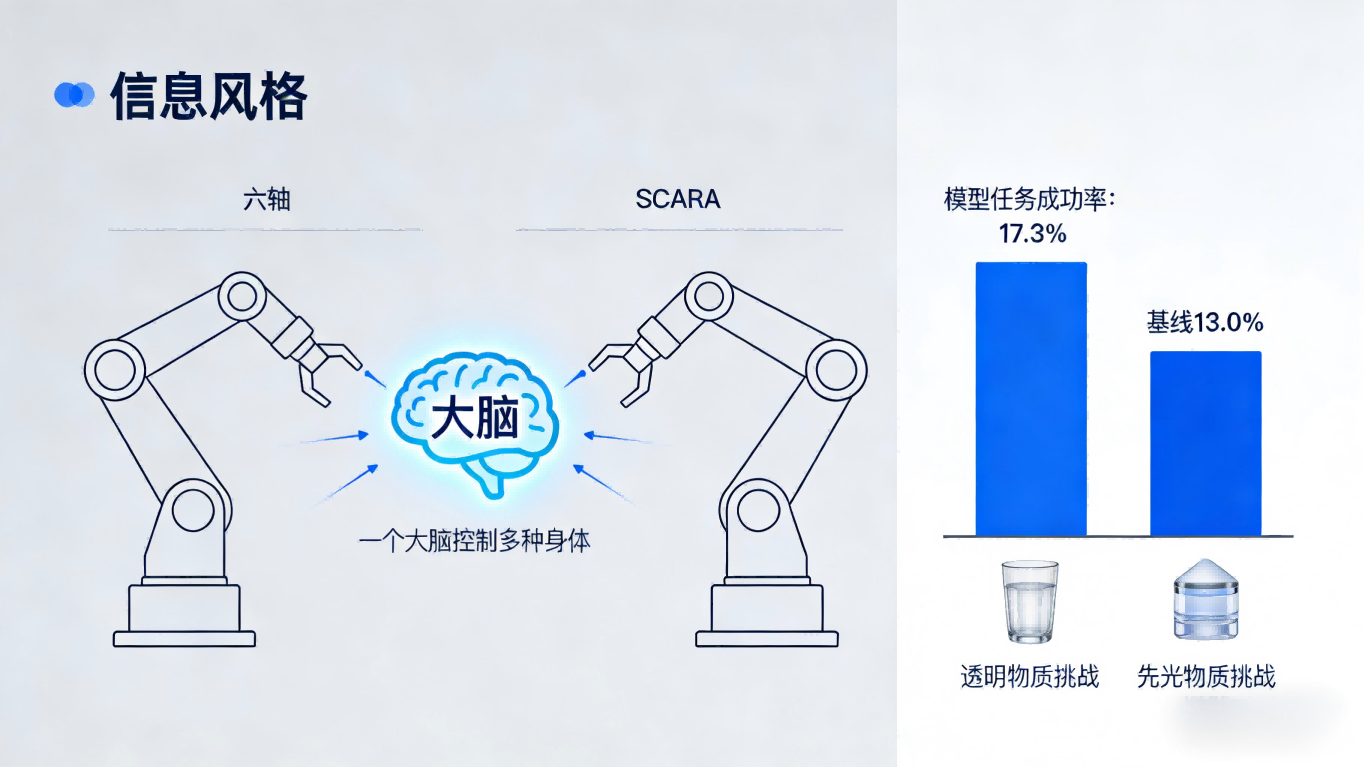
灵波科技通过大规模真机数据预训练解决了这一问题。LingBot-VLA基于 20000小时以上的真实机器人操作数据,覆盖了市场上9种主流双臂机器人构型。
这意味着同一个“大脑”可以无缝迁移到不同构型的机器人身体中。
02 性能表现
在具身智能领域公认的权威评测基准中,LingBot-VLA展现出令人瞩目的性能。
在上海交通大学开源的GM-100评测基准测试中,该模型在3个不同真实机器人平台上的跨本体泛化平均成功率从基线模型的13.0%提升至15.7%。

当模型引入深度信息后,空间感知能力得到增强,平均成功率进一步攀升至17.3%,刷新了真机评测的成功率纪录。
这证实了该模型在真实场景中的卓越性能。
03 效率革新
LingBot-VLA的核心优势不仅体现在性能上,更在于其革命性的效率提升。
该模型仅需80条演示数据即可实现高质量的任务迁移,大幅降低了下游任务的适配门槛。相比之下,传统方法往往需要数千甚至数万条标注数据。
在训练效率方面,经过深度优化的底层代码库使LingBot-VLA的训练速度达到StarVLA、OpenPI等主流框架的1.5至2.8倍。
这种效率突破意味着开发者可以用更少的计算资源和时间成本,完成模型的部署与应用。
04 协同效应
此次开源的LingBot-VLA与此前发布的LingBot-Depth模型形成了完美的“大脑”与“眼睛”组合。
LingBot-Depth专门针对机器人感知中的痛点——透明和反光物体的识别难题。
传统深度相机在遇到玻璃、镜面等材料时,往往因无法接收有效回波而产生数据丢失。
LingBot-Depth采用的“掩码深度建模”技术能利用RGB图像中的视觉上下文信息,对缺失深度区域进行智能推断与补全。
在权威基准测试中,该模型在室内场景的相对误差降低了超过70%,展现了代际级的技术优势。
05 开源实践
蚂蚁灵波此次开源不仅提供了模型权重,还同步开放了包含数据处理、高效微调及自动化评估在内的全套代码库。
这一全面开源策略大幅压缩了模型训练周期,降低了商业化落地的算力与时间门槛。
灵波科技CEO朱兴表示:“具身智能要想大规模应用,依赖高效的具身基座模型,这直接决定了是否可用以及能否用得起。”
公司通过打造InclusionAI开源生态,构建了涵盖基础模型、多模态、推理、新型架构及具身智能的完整技术体系。
在GM-100真机评测现场,搭载LingBot-VLA的机器人手臂正进行着一项复杂操作任务。
机械手指在充满透明障碍物的环境中灵活穿梭,准确识别并抓取目标物体,动作流畅而精准。旁边屏幕上的数据曲线显示,任务成功率稳定保持在行业领先水平。
随着代码和模型权重的全面开放,全球开发者社区已经开始围绕这一“机器人通用大脑”构建各种应用。
从工业生产线上的精密装配,到家庭环境中的日常协助,具身智能技术正从实验室走向广阔的现实世界。